💡 정규 표현식(正規表現式, 영어: regular expression, 간단히 regexp 또는 regex, rational expression) 또는 정규식(正規式)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다. wikipeida
문자열에서 어떤 규칙이나 패턴을 검색하거나 치환할 때 유용하게 사용할 수 있는 게 정규 표현식입니다. 또한 대부분 프로그래밍 언어에서 regex라는 라이브러리를 지원해서 문자열 관련 코딩을 더 쉽고 간편하게 할 수 있습니다. 알아두면 편리한데 쉽게 외워지지 않고 쓸데마다 찾아봄
생김새
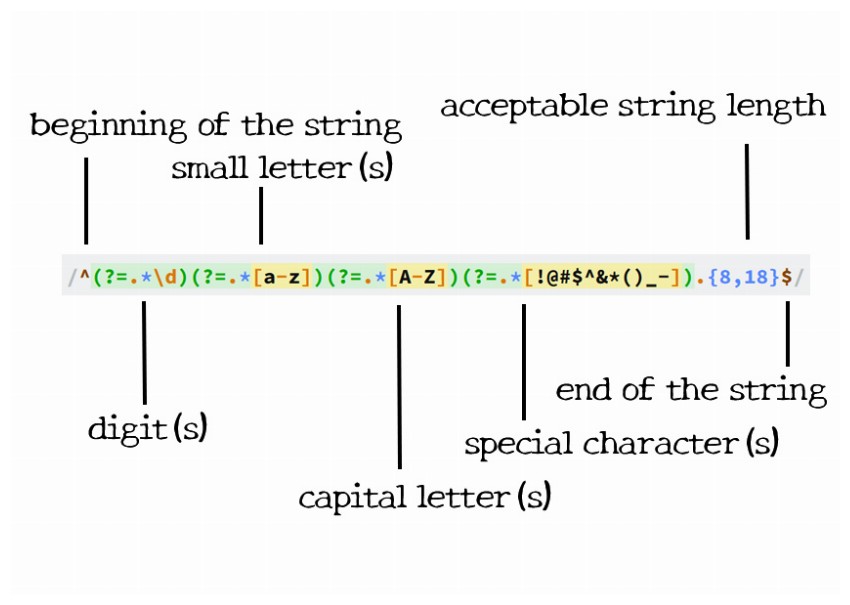
정규식은 Slash 사이에 pattern을 작성하고 마지막에 flag를 적습니다. 따라서 아래와 같은 형식으로 정규식이 표현됩니다.
/pattern/flags
/[ABC]/g
이제 pattern과 flags를 작성할줄 알면 정규표현식을 사용할 수 있습니다!
Pattern
💡 아래 소개할 패턴의 예는 모두 global 플래그를 사용했습니다.
밑에서 소개하겠지만 global옵션을 안쓰면 검사가 한번만 실행됩니다!
Character classes
💡 Character classes match a character from a specific set. There are a number of predefined character classes and you can also define your own sets.
문자 클래스들은 하나의 글자와 매칭이 됩니다.
아래 예시에서 연속으로 표기된 부분이 있는데 하나씩 연속해서 찾은 것으로 봐주세요!
| Name | Expression | Explanation | Example |
|---|---|---|---|
| Character set | [ABC] | A, B, C 중 일치하는 문자를 찾습니다. | Character clAsses |
| Negated set | [^ABC] | 일치하지 않는 문자를 찾습니다. | Character clAsses |
| Range | [A-Z] | A-Z 까지 일치하는 단어를 찾습니다. | Hello, World! |
| dot | . | 어느 문자 하나를 찾습니다. | Hello, World! |
| Word | \w | 단어 하나를 찾습니다. | Hello, World! |
| Not word | \W | 단어가 아닌 문자를 찾습니다. | Hello, World! |
| Digit | \d | 숫자 하나를 찾습니다. | 404 Not found |
| Not digit | \D | 숫자가 아닌 문자를 찾습니다. | 404 Not found |
| Whitespace | \s | 공백 하나를 찾습니다. | 404 Not found |
| Not whitespace | \S | 공백이 아닌 문자를 찾습니다. | 404 Not found |
Anchors
💡 Anchors are unique in that they match a position within a string, not a character.
문자의 위치와 관련된 표현식입니다.
| Name | Expression | Explanation | Example |
|---|---|---|---|
| Begin | ^De | De로 시작 단어를 찾습니다. | Devbin |
| End | bin$ | bin으로 끝나는 단어를 찾습니다. | Devbin |
| Word boundary | lar\b | lar로 끝나는 단어를 찾습니다. | Regular expression |
| Not word boundary | gul\B | 글자 중간에 gul 단어를 찾습니다. | Regular expression |
⚠️ 시작과 끝은 문장이 단위이며 Word boundary는 단어가 단위입니다.
💡 Tips
\b찾을 단어\b - 정확히 일치하는 단어를 찾을 수 있습니다.
\B찾을 문자열\B - 글자 사이에 포함된 문자열을 찾을 수 있습니다.
Groups & References
💡 Groups allow you to combine a sequence of tokens to operate on them together. Capture groups can be referenced by a backreference and accessed separately in the results.
여러 패턴을 묶거나 찾은 문자열을 나중에 활용할 때 사용됩니다.
| Name | Expression | Explanation | Example |
|---|---|---|---|
| Capturing group | \b(ab) | ab로 시작하는 것을 찾고 1번 그룹으로 등록합니다. | abcdeab |
| Numeric reference | \b(ab)cde\1\b | 1번 그룹의 값 ab를 가져옵니다. | abcdeab |
Quantifiers & Alternation
💡 Quantifiers indicate that the preceding token must be matched a certain number of times. By default, quantifiers are greedy, and will match as many characters as possible.
문자의 개수와 관련된 표현식입니다.
| Name | Expression | Explanation | Example |
|---|---|---|---|
| Plus | l+ | l 문자가 하나 또는 그 이상인 것을 찾습니다. | Hello, world! |
| Asterisk | \w* | 문자가 없거나 한 개 이상인 것을 찾습니다. | Hello, world! |
| Quantifier | \d{3} | 숫자가 3개인 것을 찾습니다. | H.264 |
| Optional | \w?og | 문자가 없거나 있는것을 찾습니다. | dog og |
| Alternation |
Flags
💡 Expression flags change how the expression is interpreted. Flags follow the closing forward slash of the expression
특정 옵션을 정합니다.
💡 Tips
기본적으로 global과 multiline 옵션을 많이 사용합니다!
| Name | Expression | Explanation | Example |
|---|---|---|---|
| Ignore case | /aAa/i | 대/소문자 구분을 하지 않습니다. | AaA |
| Global search | /l/g | 마지막 문자열까지 검색합니다. | Hello, world! |
| Multiline | /^abc/gm | abc로 시작하는 문자열을 찾습니다. | abca abcd abcc abcd |