💡 Quotation
고급 벡터 확장(Advanced Vector Extensions,약어:AVX)은 2008년 4월 춘계 인텔 개발자 포럼에서 발표된 x86 명령어 집합의 확장으로 SIMD명령어 집합중의 하나이다. Wikipedia
💡 TIps
단일 데이터 복수 데이터 단일 명령어 SISD SIMD 복수 명령어 MISD MIMD 해당 글에서 설명할 AVX 명령어 셋은 SIMD에 속합니다!
CPU-Z 에서 본인이 사용하는 프로세서가 사용할 수 있는 명령어 집합을 볼 수 있는데, 그 중 AVX는 큰 데이터 덩어리를 처리할 수 있는 기술로 적은 연산으로 빠르게 처리가 가능하게 합니다.
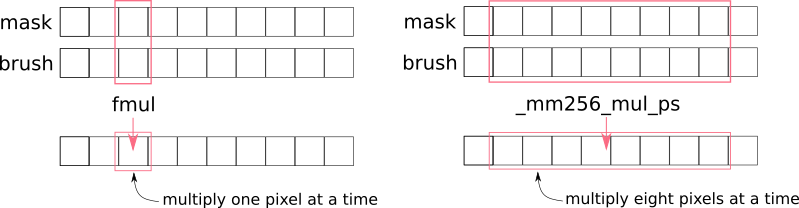
위 예제처럼 10개 원소를 가진 두 개의 배열이 있고, 두 배열의 각 원소의 합을 세 번째 배열에 넣는다고 가정한다면 왼쪽에 있는 것 처럼 총 10번의 연산이 필요할텐데, AVX 의 덩어리(Chunk)째로 처리한다면 오른쪽 있는 것 처럼 한 번의 연산만 하면 됩니다! 😄
실제로 사용해볼텐데 C/C++ 에서 emmintrin.h를 포함하여 사용할 수 있습니다.
💡 Tips
명령어 셋은 AVX 뿐 아니라 여러 명령어 셋이 있으며, 그에 해당하는 명령어 셋을 사용하려면 아래 헤더 파일을 추가해야 합니다.
1 2 3 4 5 6 7 8 9 10<mmintrin.h> MMX <xmmintrin.h> SSE <emmintrin.h> SSE2 <pmmintrin.h> SSE3 <tmmintrin.h> SSSE3 <smmintrin.h> SSE4.1 <nmmintrin.h> SSE4.2 <ammintrin.h> SSE4A <wmmintrin.h> AES <immintrin.h> AVX, AVX2, FMA
실습
두 배열의 각 원소의 합을 AVX 를 이용하여 구해보도록 하겠습니다.
| |
간단하게 a와 b 두 배열 각 원소의 합하여 c 배열에 출력하는 간단한 샘플 코드입니다. 우선 보편적으로 사용했던 Datatype으로 명령어 셋을 사용할 수 없었습니다. 😭
하지만 데이터 타입 및 함수는 Naming convension 을 갖고 있으며, 자세한 내용은 여기에서 확인하실 수 있습니다!
💡 Datatype
__m$BIT_WIDTH$$PREFIX$의 형태이며, 비트 수와 데이터 타입의 Prefix로 구성되어 있습니다. Bit width는 128, 256 등이 올 수 있으며 Prefix는 없으면float형, d가 온다면double, i가 온다면integer형을 의미합니다.예를들어
__m128i라면 4 byte(32bit) 4개의 덩어리 데이터가 된다.
💡 Function
_mm$BIT_WIDTH$_$OPERATOR$_$PARAM_DATA_TYPE$의 형태이며, 128 bit인 경우는 따로 Bit width를 써주지 않는다. Operator는 add, sub, mul, div, mask 등 연산 이름이 오며, 마지막 Parameter data type은 함수의 인자 형태를 의미합니다.