Tensor RT ❓
💡 NVIDIA® TensorRT™ is an SDK that facilitates high-performance machine learning inference. It is designed to work in a complementary fashion with training frameworks such as TensorFlow, PyTorch, and MXNet.
Tensor RT(이하 TRT) 여러 프레임워크1)로부터 생성된 모델을 최적화하여 추론 속도를 높이는 라이브러리입니다.
💡 TensorRT is integrated with PyTorch and TensorFlow so you can achieve 6X faster inference with a single line of code.
무려 한 줄의 코드로 6배나 더 빠른 추론을 할 수 있다고 하는데 안 쓸 이유가 전혀 없겠습니다!
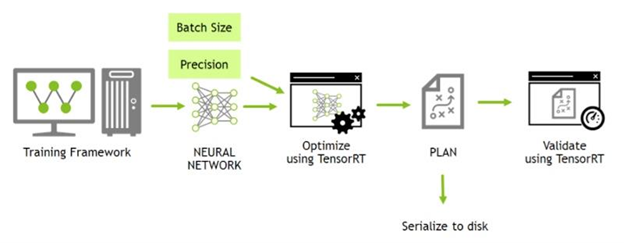
위 그림은 Tensor RT가 어떻게 동작하는지 간략하게 보여주는 그림입니다. PyTorch 또는 TensorFlow을 사용하여 학습된 모델을 Neural networkcuDNN?을 만들어 최적화한 후 Engine을 생성, 이렇게 만들어진 Engine으로 추론을 하게 됩니다.
위 상황이 실제 코드에서 어떻게 흘러가는지 보기 위해 개발 환경을 설정하겠습니다.
Environment ⚙️
💡 Tensor RT는 C++ 또는 Python 으로 제공되는데 이 글에서는 C++ 을 사용하겠습니다.
- Windows 10 pro 64bit
- Visual C++ 2015 (v140)
- nVIDIA RTX 3070 (Arch ampere compute_86,sm_862))
- CUDA 11.3
- cuDNN 8.4.1
- TensorRT 8.4.1.5
⚠️ Warning 본인의 그래픽 카드와 호환이 되는 CUDA 버전을 먼저 설치하고 CUDA 버전에 맞게 cuDNN과 Tensor RT를 설치해주세요!
그래픽 카드별 CUDA 호환 목록은 여기에 있습니다.
Process 💻
nvInfer1 이라는 namespace를 사용하며 prefix 로 ‘I’를 사용합니다. 대충 nvinfer1::I 치면 intelisense 나온다는 뜻
위 Tensor RT 동작 그림이 라이브러리를 사용하면 아래와 같이 표현됩니다.
Build 🏗️
TRT 객체를 생성하기 위해 아래와 같은 작업을 합니다.
- TRT 전용 로그 ILogger 생성
- builder 생성 -
nvinfer1::createInferBuilder(TRT Logger) - network optimizing 및 생성 -
builder->createNetworkV2(kEXPLICIT_BATCH) - parser 생성 -
nvonnxparser::createParser(network, logger) - config 생성 -
builder->createBuilderConfig() - destory
💡 학습된 모델로 Neural network를 만드는데 이때 로드 되는 모델이 onnx3) 이었기 때문에 onnx parser를 사용했습니다.
Deserializing a plan
- runtime 생성
- engine 생성
- context 생성
💡 최종적으로 최적화된 Neural network와 config 객체로 engine을 생성합니다. 이때 engine은 file로 저장할 수 있습니다. 웬만하면 저장하세요. 파싱하고 최적화하는데 느립니다!
Set buffer
- engine 바인딩 개수(input/output)만큼 차원 및 데이터 타입 세팅
void **buffer;cudaMalloc()을 이용하여 device bufferCPU 전용 생성malloc()를 이용하여 host bufferGPU 전용 생성
💡 Model을 로드할 때 바인딩 개수 및 데이터 타입을 알 수 있습니다. 이를 이용하면 버퍼를 자동으로 생성할 수 있습니다.
Inference 🔍
cudaMemCpy()를 이용하여 input data 전달 host to device- context를 이용하여 추론 시작
cudaMemCpy()를 이용하여 output data 전달 device to host- output data로 결과 도출 softmax, NMS 등
참고
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit
각주
- TensorFlow, Keras, pyTorch, sonnet, mxnet 등이 있다. ↩
- The compute capability identifies the features supported by the GPU hardware. 그래픽 카드가 어느 기능까지 쓸 수 있는지 식별해놓은 숫자 ↩
- Open Neural Network Exchange는 AI 분야의 혁신과 협업을 촉진하기 위해 기계 학습 알고리즘 및 소프트웨어 도구를 나타내는 공개 표준을 설정하는 기술 회사 및 연구 기관의 오픈 소스 인공 지능 생태계입니다. wikipedia ↩